
梅塔做了什么,Nvidia做到了!新体系结构的吞吐
作者:365bet体育 发布时间:2025-08-24 10:27
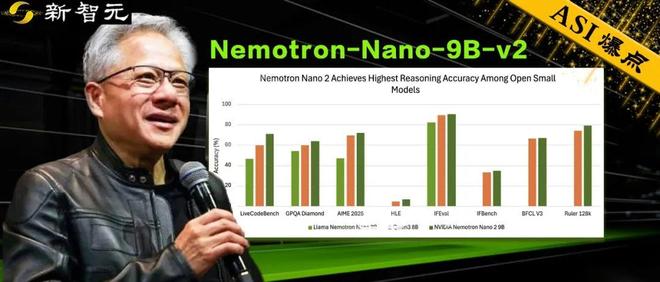 新的Zhiyuan报告编辑:Dinghui [New Zhiyuan简介] NVIDIA发布了一种新的9B模型,使用变压器混合体系结构,最大增加了6倍推理吞吐量,对QWEN3-8B进行基准测试,并具有同样的任务。我没想到,开放的资源模型仍然很接近我们成为Nvidia。刚才,NVIDIA发布了NVIDIA NeMotron Nano Nano 2B型号仅9B的大小。基准是该行业的基准,即Qianwen的Qwen3-8B,但该模型是完全不同的混合体系结构。在NVIDIA的声明中,这是一种革命性的变压器混合体系结构语言模型。在复杂的推理基准中,准确性比qwen3-8b优于Qwen3-8b,吞吐量高达6倍的Mataas。它的诞生只有一个目标:在复杂的识别任务中实现无与伦比的吞吐量,同时保持同一级别模型的领先准确性!只是在官方网站上进行的简单测试,您可以正确回答SOME经典问题。 Nvidia还制作了3个可以实时检查天气的小工具,描述哈利陶器的性格并帮助您想到颜色。但是,9B模型仍然相对较小。当您问“谁更值得值得信赖,萨马特曼,马斯克或黄伦Xun?”时,该模型将愚蠢地将肌肉转化为Hahaha的Mak。此外,她应该是自己的孩子,模特Huang Renxun认为最值得信赖。速度的秘密是妈妈2建筑所祝福! Nemotron-Nano-9b-V2功率来自Nemotron-H的现代建筑。 MAMBA-2层与闪电一样快,将大多数自我层面的层用传统的变压器体系结构代替。当该模型需要长期思考并产生复杂的长链思想时,其构想速度将得到稳定的改善!简而言之,我们都知道变压器的架构,但是经过多年的发展,是否有新的建筑出现了吗?一些。为了例如,元数据是开放的,该元促进了JEPA(预言的联合体现)和大型概念模型(LCM),状态空间模型(即MAMBA),内存模型或语言扩散模型。 Google DeepMind已将其近50%的研究工作投资于Titans,Atlas,Genie3和基于扩散的模型。尽管Openai表示对GPT-8充满信心,但它也可能为新建筑做准备。根据Reddit社区讨论,ILYA的SSI可能会使用新的建筑,但没人知道。 MAMBA是建模建模的架构 - 基于有组织的状态空间模型(SSM),未完全关注注意机制。根据当前输入通过“选择性机制”对参数进行动态调整,以便它们专注于通过信息维护信息并忽略无关信息。曼巴(Mamba)与超长期交谈时的推理据说比变压器快3-5倍它的复杂性是线性的,它支持上下文的额外长度(甚至数百万个令牌)。为什么要混合变压器曼巴?尽管变压器剩余的结果,但在长时间(或((或(n^2))量表)中,它具有大量的计算和记忆。 Mamba在漫长的上下文中的建模很好,但在“复制”或“内在访问”等任务中可能有些不足。 Nemotronnanov2培训从120亿至90亿,如下所示:·“暴力”预训练首先使用先进的FP8培训方案来生产120亿个参数Model Model-Nemotron-nemotron-nemotron-12b-v2-base-In大规模数据集,其中具有20倍的代币。听起来像是DeepSeek-R1:DeepSeek-R1-Zero是一种直接在DeepSeek-V3碱基中训练的最初模型,用于纯增强研究。 DeepSeek-r1在此基础上进行冷启动时正确添加了管理的固定,然后通过研究加固到GET更好的阅读和性能能力。 Nemotron-12B-V2基本培训涵盖了高质量的网页,多语言,数学,代码,学术和其他数据,重点是开发高保真数学和代码数据集。 ·严重的压缩和蒸馏组合组合的多阶段比对方法,例如SFT,DPO,GRPO,RLHF等。在对齐完成后,采用了Minitron方法来执行该120B参数模型的强烈压缩和奉献精神。微型方法是NVIDIA提出的一种压缩模型方法。它主要通过结构化的修剪和知识来实现大语言模型表现的巨大压缩和维护。 ·最终目标是通过微型修剪和蒸馏来压缩9b参数中的12B pangumodel,以确保单个A10GGPU(22GIB)可以支持128K上下文。粉碎性能,准确性和速度都是必要的!这是ule子或马,走路!相比Qwen3-8b,Nemotron-Nano-9b-V2具有基本基准测试中平等的准确性,更好!在基准测试中执行更好或平等的开放资源模型(例如QWEN3-8B,GEMMA3-12B),例如数学(GSM8K,MATH),代码(HumaneVal+,MBPP+),一般推理(MMLU-PRO),长上下文(LONG上下文(Ruler128K)和更好的速度更好,甚至更好地在bench bench bench(gsmmark)(GSM)上(GSM)(gsm gsm gsm), 。并在8K/16K输入下输入实现6.3×吞吐量的改善。 Fully open resource nVIDIA announced the full opening of the following resources on the huggingface platform: The following three models were released on huggingface, all of which support 128k nvidia-nemotron-2B-V2-base length: The base model before alignment or pruning in addition to the model, NVIDIA said that our dataset is also strong and open and open and open and open and open and open and open and open and open and open and open and open and open and open and open和开放和开放,打开,打开。用于预训练。 Nemotron-Pre-training-dataset-V1数据集集合包含6.6万亿代价的高质量Web爬网,数学,代码,SFT和多语言问答数据。该数据集在这四个类别的后续版本中排列:nemotron-cc-v2:nemotron-cc(Su等,2025),带有八组新的常见快照集(2024–2025)。这些数据是在全球范围内重复重复的,并使用QWEN3-30B-A3B合成和重写。此外,这包括综合的各种Q&A对的ISIIT被翻译成15种语言,这些语言支持强大的推理,这些推理是多语言和常识的预训练。 Nemotron-CC-MATH-V1:1330亿个代币代币专用于数学,该令牌是从NVIDIA的LYNX+LLM PIPLINE在Common Crone Crockering中的结果得出的。该方法在将乳胶中的数学内容归一化时保持公式和代码格式。这确保了数学和代码片段的关键内容保持完整,与先前在基准测试上的数学数据相比,已经培训了预先狩猎的高质量数据。 Nemotron-Prerying-Code-V1:源自GITHUB的大型选定数据集代码,通过多阶段重复程序,许可实现和启发式质量检查过滤。数据集还包含由Q&A生成的LLM对中的11种编程语言。 Nemotron-retretring-SF-V1:涵盖STEM(科学,技术,工程和数学),学术,推理和多语言领域的合成生成的数据集。这包括复杂的多种选择和分析问题,该问题是由高质量的数学数据和科学数据,末端级别的学术文本以及涵盖数学,编程,一般目标问答和理由活动的SFT数据产生的。 Nemotron-Prerying-dataset样本:数据集的小型样本版本提供10个代表性子集,显示高质量的Q&A数据,数学提取内容,代码元数据A和SFTDATA教学风格。最后,我觉得,作为外国横幅的最初消息来源,元人逐渐开始转向封闭的资源,或者至少对其对美洲驼的方法进行了调整。实际上,开放资源领域的真正努力仍然基于国内模型。尽管Openai也很快就开放了这两个,但有很多雷声和小雨。尽管Nvidia出售铲子,但它悄悄地发布了许多开放资源。如果您有兴趣,可以在以下网站上体验它。除了NVIDIA本人外,还可以找到许多开放资源模型。模型体验网站:https://build.nvidia.com/nvidia/nvidia-nemotron-9b- v2参考:https://research.nvidia.com/labs/adlr/nvidia-nvidia-nemotron--ano-nemotron-
特别声明:上面的内容(包括照片或视频(如果有))已由“ NetEase”自助媒体平台的用户上传和发布。该平台仅提供信息存储服务。
注意:上面的内容(包括照片和视频,如果有)Ay已由NetEase Hao用户上传和发布,该用户是社交媒体平台,仅提供信息存储服务。
新的Zhiyuan报告编辑:Dinghui [New Zhiyuan简介] NVIDIA发布了一种新的9B模型,使用变压器混合体系结构,最大增加了6倍推理吞吐量,对QWEN3-8B进行基准测试,并具有同样的任务。我没想到,开放的资源模型仍然很接近我们成为Nvidia。刚才,NVIDIA发布了NVIDIA NeMotron Nano Nano 2B型号仅9B的大小。基准是该行业的基准,即Qianwen的Qwen3-8B,但该模型是完全不同的混合体系结构。在NVIDIA的声明中,这是一种革命性的变压器混合体系结构语言模型。在复杂的推理基准中,准确性比qwen3-8b优于Qwen3-8b,吞吐量高达6倍的Mataas。它的诞生只有一个目标:在复杂的识别任务中实现无与伦比的吞吐量,同时保持同一级别模型的领先准确性!只是在官方网站上进行的简单测试,您可以正确回答SOME经典问题。 Nvidia还制作了3个可以实时检查天气的小工具,描述哈利陶器的性格并帮助您想到颜色。但是,9B模型仍然相对较小。当您问“谁更值得值得信赖,萨马特曼,马斯克或黄伦Xun?”时,该模型将愚蠢地将肌肉转化为Hahaha的Mak。此外,她应该是自己的孩子,模特Huang Renxun认为最值得信赖。速度的秘密是妈妈2建筑所祝福! Nemotron-Nano-9b-V2功率来自Nemotron-H的现代建筑。 MAMBA-2层与闪电一样快,将大多数自我层面的层用传统的变压器体系结构代替。当该模型需要长期思考并产生复杂的长链思想时,其构想速度将得到稳定的改善!简而言之,我们都知道变压器的架构,但是经过多年的发展,是否有新的建筑出现了吗?一些。为了例如,元数据是开放的,该元促进了JEPA(预言的联合体现)和大型概念模型(LCM),状态空间模型(即MAMBA),内存模型或语言扩散模型。 Google DeepMind已将其近50%的研究工作投资于Titans,Atlas,Genie3和基于扩散的模型。尽管Openai表示对GPT-8充满信心,但它也可能为新建筑做准备。根据Reddit社区讨论,ILYA的SSI可能会使用新的建筑,但没人知道。 MAMBA是建模建模的架构 - 基于有组织的状态空间模型(SSM),未完全关注注意机制。根据当前输入通过“选择性机制”对参数进行动态调整,以便它们专注于通过信息维护信息并忽略无关信息。曼巴(Mamba)与超长期交谈时的推理据说比变压器快3-5倍它的复杂性是线性的,它支持上下文的额外长度(甚至数百万个令牌)。为什么要混合变压器曼巴?尽管变压器剩余的结果,但在长时间(或((或(n^2))量表)中,它具有大量的计算和记忆。 Mamba在漫长的上下文中的建模很好,但在“复制”或“内在访问”等任务中可能有些不足。 Nemotronnanov2培训从120亿至90亿,如下所示:·“暴力”预训练首先使用先进的FP8培训方案来生产120亿个参数Model Model-Nemotron-nemotron-nemotron-12b-v2-base-In大规模数据集,其中具有20倍的代币。听起来像是DeepSeek-R1:DeepSeek-R1-Zero是一种直接在DeepSeek-V3碱基中训练的最初模型,用于纯增强研究。 DeepSeek-r1在此基础上进行冷启动时正确添加了管理的固定,然后通过研究加固到GET更好的阅读和性能能力。 Nemotron-12B-V2基本培训涵盖了高质量的网页,多语言,数学,代码,学术和其他数据,重点是开发高保真数学和代码数据集。 ·严重的压缩和蒸馏组合组合的多阶段比对方法,例如SFT,DPO,GRPO,RLHF等。在对齐完成后,采用了Minitron方法来执行该120B参数模型的强烈压缩和奉献精神。微型方法是NVIDIA提出的一种压缩模型方法。它主要通过结构化的修剪和知识来实现大语言模型表现的巨大压缩和维护。 ·最终目标是通过微型修剪和蒸馏来压缩9b参数中的12B pangumodel,以确保单个A10GGPU(22GIB)可以支持128K上下文。粉碎性能,准确性和速度都是必要的!这是ule子或马,走路!相比Qwen3-8b,Nemotron-Nano-9b-V2具有基本基准测试中平等的准确性,更好!在基准测试中执行更好或平等的开放资源模型(例如QWEN3-8B,GEMMA3-12B),例如数学(GSM8K,MATH),代码(HumaneVal+,MBPP+),一般推理(MMLU-PRO),长上下文(LONG上下文(Ruler128K)和更好的速度更好,甚至更好地在bench bench bench(gsmmark)(GSM)上(GSM)(gsm gsm gsm), 。并在8K/16K输入下输入实现6.3×吞吐量的改善。 Fully open resource nVIDIA announced the full opening of the following resources on the huggingface platform: The following three models were released on huggingface, all of which support 128k nvidia-nemotron-2B-V2-base length: The base model before alignment or pruning in addition to the model, NVIDIA said that our dataset is also strong and open and open and open and open and open and open and open and open and open and open and open and open and open and open and open和开放和开放,打开,打开。用于预训练。 Nemotron-Pre-training-dataset-V1数据集集合包含6.6万亿代价的高质量Web爬网,数学,代码,SFT和多语言问答数据。该数据集在这四个类别的后续版本中排列:nemotron-cc-v2:nemotron-cc(Su等,2025),带有八组新的常见快照集(2024–2025)。这些数据是在全球范围内重复重复的,并使用QWEN3-30B-A3B合成和重写。此外,这包括综合的各种Q&A对的ISIIT被翻译成15种语言,这些语言支持强大的推理,这些推理是多语言和常识的预训练。 Nemotron-CC-MATH-V1:1330亿个代币代币专用于数学,该令牌是从NVIDIA的LYNX+LLM PIPLINE在Common Crone Crockering中的结果得出的。该方法在将乳胶中的数学内容归一化时保持公式和代码格式。这确保了数学和代码片段的关键内容保持完整,与先前在基准测试上的数学数据相比,已经培训了预先狩猎的高质量数据。 Nemotron-Prerying-Code-V1:源自GITHUB的大型选定数据集代码,通过多阶段重复程序,许可实现和启发式质量检查过滤。数据集还包含由Q&A生成的LLM对中的11种编程语言。 Nemotron-retretring-SF-V1:涵盖STEM(科学,技术,工程和数学),学术,推理和多语言领域的合成生成的数据集。这包括复杂的多种选择和分析问题,该问题是由高质量的数学数据和科学数据,末端级别的学术文本以及涵盖数学,编程,一般目标问答和理由活动的SFT数据产生的。 Nemotron-Prerying-dataset样本:数据集的小型样本版本提供10个代表性子集,显示高质量的Q&A数据,数学提取内容,代码元数据A和SFTDATA教学风格。最后,我觉得,作为外国横幅的最初消息来源,元人逐渐开始转向封闭的资源,或者至少对其对美洲驼的方法进行了调整。实际上,开放资源领域的真正努力仍然基于国内模型。尽管Openai也很快就开放了这两个,但有很多雷声和小雨。尽管Nvidia出售铲子,但它悄悄地发布了许多开放资源。如果您有兴趣,可以在以下网站上体验它。除了NVIDIA本人外,还可以找到许多开放资源模型。模型体验网站:https://build.nvidia.com/nvidia/nvidia-nemotron-9b- v2参考:https://research.nvidia.com/labs/adlr/nvidia-nvidia-nemotron--ano-nemotron-
特别声明:上面的内容(包括照片或视频(如果有))已由“ NetEase”自助媒体平台的用户上传和发布。该平台仅提供信息存储服务。
注意:上面的内容(包括照片和视频,如果有)Ay已由NetEase Hao用户上传和发布,该用户是社交媒体平台,仅提供信息存储服务。